Learning and Practicing Agent Skills
Preface
Notes for myself on why agent skills matter and what I gain after setting them up.
A Simple Mental Model
In a normal chat, token usage grows roughly linearly with each turn.
// First turn:
User: Hi.
AI sees: Hi there.
// Next turn:
User: Hi.
AI sees: Hi there.
User: What's the weather today?
AI sees: Hi + Hi there + What's the weather today?
Once context gets large enough, the model compresses earlier turns to cut per-turn token cost.
I think rules and skills mainly help with:
- Saving tokens, I am a poor guy.
- Avoiding repeating the same instructions every session.
For example you might set:
- rule: ignore routine “hi” greetings each time
- skill: apply my polite tone/persona
Token usage might then look like:
User: Hi.
AI sees: Hi there.
User: What's the weather today?
AI sees: "Hi, Hi there." (greeting de-emphasized but politeness retained) + What's the weather today?
Skills
Chinese vs English in Prompts
Day to day I mostly chat in Chinese, but when I asked GPT, the advice was to write skills in English.
These words are conventional in agent prompts:
| Keyword | Typical model reading |
|---|---|
| MUST | Mandatory |
| NEVER | Forbidden |
| ALWAYS | Must execute |
| ONLY | Scope limit |
| DO NOT | Forbidden |
| REQUIRED | Required |
| BEFORE | Prerequisite step |
| AFTER | Follow-up step |
The Matt Pocock Stack
I recently came across Matt’s workflow. The talk is great—he’s just a bit chatty. I picked up a few skills and plan to practice them with my own tweaks:
/grill-me/to-prd/to-issue/tdd
The flow:
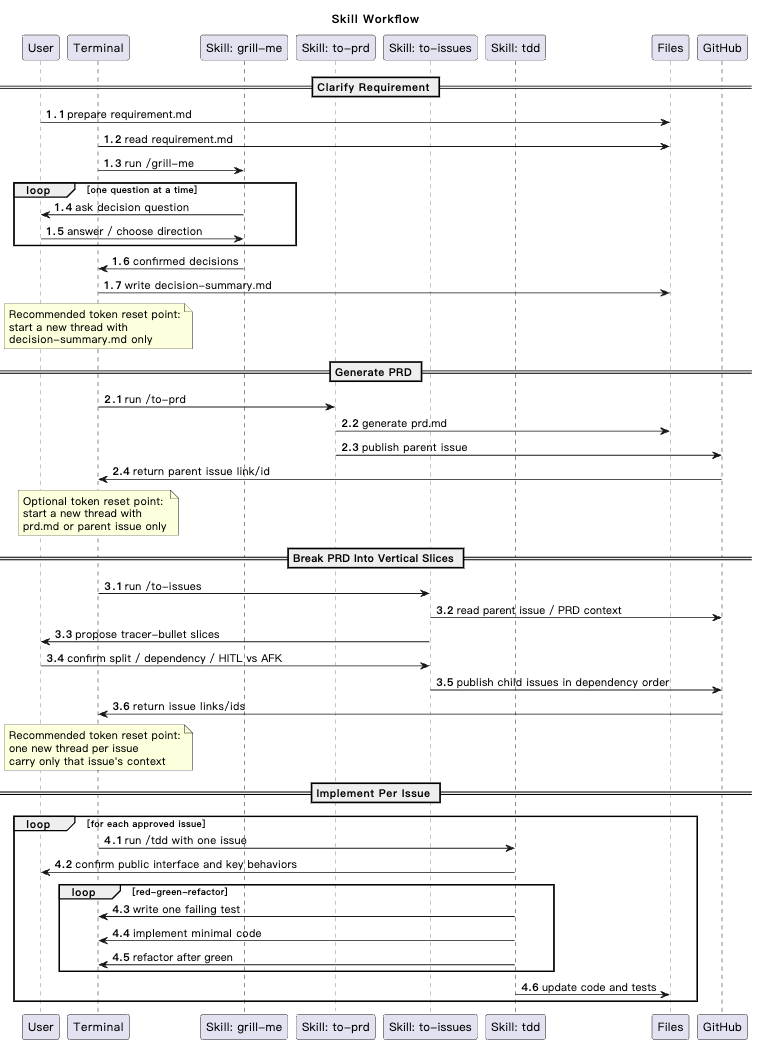
On the diagram I marked where each big block can end with a new agent chat or clearing history, to save tokens and keep context smaller.
I won’t paste full skill bodies here; everything is open source: mattpocock/skills.
grill-me
---
name: grill-me
description: Interview the user relentlessly about a plan or
design until reaching shared understanding, resolving each branch of the decision tree. Use when user wants to stress-test a plan, get grilled on their design, or mentions "grill me".
The idea is simple: reach shared understanding.
PlanMode exists now, but a plan doc from it is often not granular enough—and easy to end up as a wall of text I rarely read end to end.
Single-question Q&A forces you to think through requirements step by step.
I mainly use Cursor and added: Use select UX to decide the answer. so the built-in agent tools are easier to use.
to-prd and to-issues
---
name: to-prd
description: Turn the current conversation context into a PRD and publish it to the project issue tracker. Use when user wants to create a PRD from the current context.
--
---
name: to-issues
description: Break a plan, spec, or PRD into independently-grabbable issues on the project issue tracker using tracer-bullet vertical slices. Use when user wants to convert a plan into issues, create implementation tickets, or break down work into issues.
---
These pair naturally: shape work into a standard format → push to GitHub → use as pre-dev guidance.
In agile terms, to-prd is roughly feature/sprint-level spec; to-issues is the breakdown underneath.
Worth calling out:
- He tags issues with AFK (away from keyboard) vs HITL (human-in-the-loop)—AI can start immediately on AFK; HITL needs you (e.g. Supabase console work or answering detail questions).
- When splitting issues he stresses vertical slices. Example: login/sign-up module. AI might propose a horizontal split:
1. UI for login, sign-up, forgot-password pages
2. APIs and DB for login, sign-up, forgot-password
3. Integration and testing
4. ...
That’s weak because you can’t test or get feedback until step 3. A better vertical split:
1. Login end-to-end (front + back), test
2. Sign-up end-to-end, test
3. Forgot-password end-to-end, test
4. Component polish
TDD
---
name: tdd
description: Test-driven development with red-green-refactor loop. Use when user wants to build features or fix bugs using TDD, mentions "red-green-refactor", wants integration tests, or asks for test-first development.
Rather than “a skill,” TDD is closer to a design stance: write a failing red test → implement → all reds green.
The same theme showed up in the popular superpowers repo.
I had GPT compare the two:
The superpowers
test-driven-developmentskill reads like a TDD rulebook. Emphasis:
- Tests first, always
- You must see tests fail
- If tests didn’t fail first, it wasn’t TDD
- If you wrote production code first, delete and restart
- Strong pushback on “add tests later” and “skip just this once”
- Extra docs on mock anti-patterns
Matt Pocock’s
/tddreads like TDD for real projects. Emphasis:
- Tests assert public APIs and user-observable behavior
- Don’t test implementation details, private methods, or internal collaborators
- Confirm API changes, important behaviors, and test priorities with the user first
- One vertical slice at a time: one test, one implementation
- Push back on writing all tests then all code
- On refactor: module boundaries, deep modules, testability
In one line:
The GitHub version checks whether you actually did TDD.
/tddchecks whether your tests are good and the flow fits a real codebase. I’d default to/tddand keep two hard rules from the GitHub version: must see failure first, and failure must be for the right reason.
Workflow in Practice
I ran /grill-me → /to-prd → /to-issues → /tdd to build a new cross-border e-commerce storefront in the past half of month, entirely in Cursor—first Composer 2, then Composer 2.5 when it landed last week.
So far I’m happy; issues all live on GitHub.
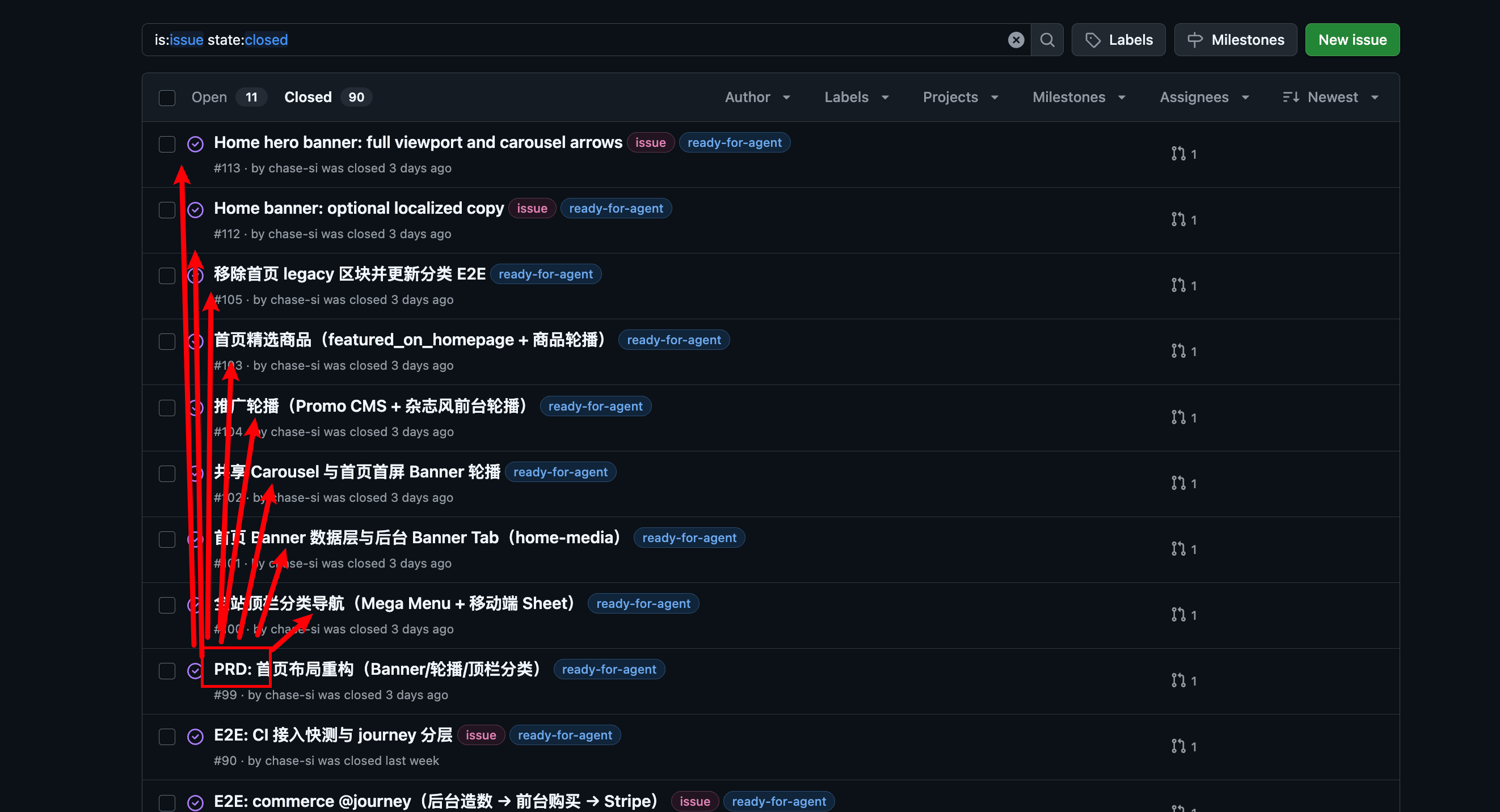
My git flow:
- Checkout branch
prd(feature-*/refactor-*/...)frommain - After Step1, checkout branch per issue from
prd - Each issue ->
prdwith PR; auto-merge or review depending on risk - When PRD issues are done, I focus on tests or manual QA, then add fix-up issues on
prdas needed
The diagram shows prd and issue branches separately—easy revert and progress tracking.
Models: Trade-offs
Composer is very cheap next to GPT-5.5 and Opus 4.7. Composer handles ~95% of tasks. When it’s stuck, switching models often still burns tokens in loops. I’m on the $20/month tier, so I usually stop and intervene manually.
Sometimes I use GPT-5.5 for architecture review, or multi-model discussion during design challenging tasks.
Where Humans Still Matter
- I carefully review PRD → issues: each issue should be a small closed loop, at least self-testable when done.
- When AI says the PRD is complete, I focus on tests. I mostly skip exhaustive unit/component coverage reviews and look at Playwright E2E—like staged demos in the old “manual QA per feature” world.
- Polish: form validation copy, visual feel—you still click through and ask AI to improve.
Other thoughts
We still face the issue The page design by AI looks too AI. I think the new models will improve it step by step.
I tried base44 recently, it's already not too AI, it generated by my a single sentence description: show me a website selling swimwear.
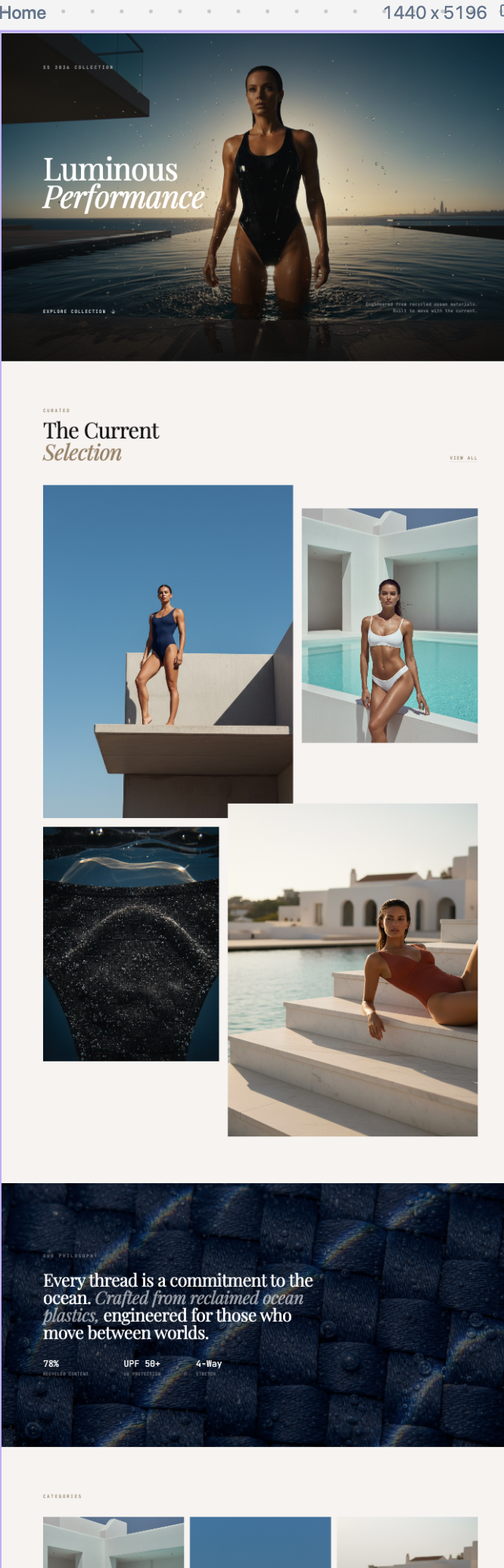
But I also see a lot of complain that the website only deliver frontend, not all codes, which require the users have to spend more money it on it to use tokens to do the further adjustment.
But in the long run, I believe AI cannot learn aesthetics. I find it hard to imagine how AI could judge whether a 0.3s Ease In-Out animation or a 0.2s Linear animation feels better. If it's just copying, different combinations and styles will result in different feelings.
AI lets us feel we can do anything more than ever, but the life doesn't get better.